How does the number of lawyers in North Carolina relate to US suicides?
Data correlation is when two sets of data appear to match closely. Data correlation is a key technique in artificial intelligence and data science. It’s used to identify patterns in data, and suggest relationships from which we can infer meaning.
So what do you make of this?
The answer is . . .
Meaning a near-perfect match between the numbers of lawyers in North Carolina, and suicides by hanging, strangulation and suffocation in the US
Don’t believe it? Scroll down to see the data
Here’s the “evidence”:
Public data shows that for the first decade of this century, the number of lawyers in the state of North Carolina grew at almost exactly the same rate as the number of suicides by hanging, strangulation and suffocation.
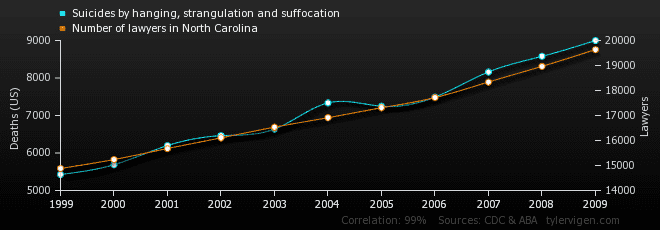
What does this data correlation mean?
If you knew nothing about lawyers or suicide, it might be tempting to try to figure out why the two figures match so closely, and speculate on what causes them to correlate.
But of course in terms of a relationship between lawyers and suicides, the data actually means nothing at all.
Is there a serious point?
So the example is deliberately extreme. But it does illustrate a serious consideration for data science work. It’s particularly relevant for business people new to data science.
What it demonstrates is that
just because two sets of numbers match, they’re not necessarily related. And if they are, you can’t infer from the data what the relationship is.
In other words, the difference between data correlation, causality and coincidence.
It might seem obvious in this example. But if the chart axes were product sales against customer income, you’d probably expect data correlation to indicate a valid relationship.
Now how about product sales against postcode? Perhaps, but maybe not. We can’t tell without knowing some more about the product and why people buy.
What about product sales against eye colour or number of cars in the household?
The more complex the model, the more difficult the judgements involved. It very quickly can stop being “obvious” what the data is trying to say.
So you could spend a lot of time trying to understand a coincidence, or overlook a powerful insight about your business.
One reason data scientists can earn large salaries is because of the skills required to unravel this kind of situation.
This all comes into its own when AI finds surprising correlations in your data . . .
🙂
Want to find out more about how data can provide insights for business?
You might find these articles useful



